

Il n'y a plus d'informaticien.
Il n'y a plus d'informaticien.
Il y a des banquiers qui codent.

MemoBank est une start-up française qui propose aux TPE/PME un service de banque en ligne.
Dans une interview récente, Jean-Daniel Guyot (l’un des cofondateurs) explique avoir choisi de construire le système d’information complet de MemoBank à partir de zéro.
Pourquoi ce choix risqué et coûteux (3 ans de développement), plutôt que d’acheter une solution clé en main déjà éprouvée par les banques traditionnelles ?
Jean-Daniel Guyot évoque quelques raisons :
Pour recentrer le système sur la relation client, et masquer autant que possible la complexité des exigences réglementaires bancaires,
Pour faciliter la vie des conseillers. Leur vrai métier n’est pas de jongler entre plusieurs applications, ni de faire des copier/coller, ni d’expliquer à leurs clients qu’il faut prendre son mal en patience.
Centraliser et fiabiliser les données pour les mettre à disposition en temps-réel.
Dans le contexte actuel “il existe toujours déjà un truc pour faire ça”, je suis admiratif face à cette ambition de construire un SI bancaire à partir d’une feuille blanche.
Car contrairement à la livraison de paniers de légumes en circuit court, ou au coaching de régime minceur, un service bancaire n’a pas droit à l’erreur.
L’exigence de qualité, de fiabilité, mais aussi de performance (on ne va pas attendre 5 minutes pour déterminer si mon paiement par carte bancaire est accepté) sont à un très haut niveau.
Dans un article publié sur le blog de MemoBank, on peut lire les principes d’architecture retenus pour les fondations d’un tel système.
Le cocktail est le pattern CQRS/ES, qui combine deux approches qui se marient à merveille :
Event sourcing (ES)
Command Query Responsibility Segregation (CQRS)
En synthèse :
Plutôt que de mettre les données au centre de l’application, on y place les événements qui servent à modifier des données.
Ainsi, la valeur d’une donnée à un instant T est déduite de l’historique de tous les événements jusqu’à l’instant T.
Il est simple de créer une nouvelle donnée à partir d’un même historique d’évènements. Il suffit de décrire la fonction à appliquer à cette donnée en réaction à chaque type d’évènement, puis de “rejouer le film”.
Les requêtes qui ont besoin de lire les données sont indépendantes des événements qui les modifient.
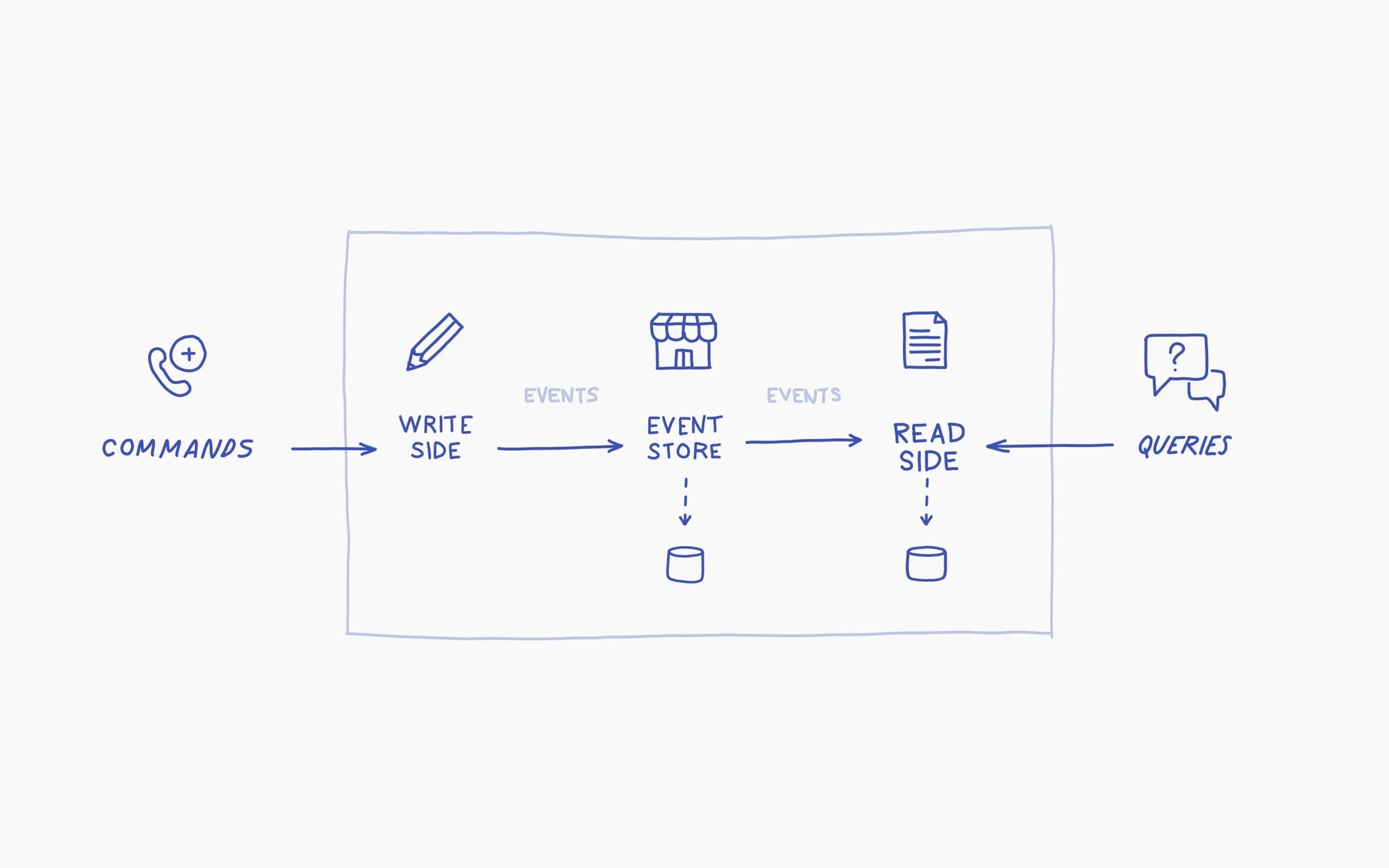
Illustrons cela par un exemple :
“Emettre une facture”, et “Emettre un devis” sont des événements. Ils comportent un n° de compte client, une date, et un montant.
Le comptable de l’entreprise veut voir l’en-cours des comptes de chaque client. Ces données sont calculées à partir de l’historique des évènements “Emettre une facture”.
Le responsable commercial qui s’occupe du client veut voir ce qui a été facturé, mais aussi le contenu du pipe commercial. Ces données sont calculées par les deux types d’évènement.
Le responsable de la stratégie veut actualiser un objectif de chiffre d’affaire pour mettre à jour son business Plan. Ces données sont calculées par l’historique des devis émis.
Trois profils, trois besoins différents de données. Mais un historique commun d’événements.
Pourquoi ce choix d’architecture pour une banque ?
Soyons honnête, il y avait quand même plus simple.
On pouvait faire comme d’habitude, avec une grosse base de données relationnelle au centre de l’application, dans laquelle on stocke les comptes bancaires et la liste des opérations. Et tout le monde va lire et écrire dedans.
Et bien non.
Pas cette fois.
Car une architecture CQRS/ES convient peut-être mieux à un système d’information bancaire d’une start-up :
Puisqu’on centralise l’historique non modifiable des événements plutôt que les valeurs, on construit un système intrinsèquement fiable et auditable. On peut justifier chaque valeur.
Le système est très performant : on peut traiter un événement, sans attendre les modifications de données qu’il va engendrer, ni être bloqué par des lectures simultanées. De l’autre coté, on peut afficher très rapidement les données souhaitées.
C’est évolutif : de nouvelles données sont faciles à ajouter pour répondre aux besoins des clients et des conseillers.
C’est plus simple à tester, car les flux d’informations sont mieux isolés les uns des autres.
En contrepartie, il faut s’habituer à la désynchronisation entre les événements et les données. Et là ça peut faire mal.
Par exemple, lorsqu’on reçoit un événement “effectuer un retrait de 50€ au distributeur”, il faut connaître le solde du compte bancaire pour répondre positivement ou non. Le problème est que cette valeur n’est peut-être pas encore tout à fait à jour, car il y a un achat sur Internet qui a donné lieu à une transaction juste avant.
Pour une application bancaire, les cas de ce type à traiter peuvent être peu nombreux. Mais ça pourrait devenir un casse-tête pour un autre contexte métier.
C’est le métier qui conditionne l’architecture.
La façon dont on organise son système informatique n’est pas seulement l’affaire d’un prestataire externe. Il n’est pas déterminé par le dernier framework à la mode, ni par les habitudes des développeurs avec lesquels on travaille.
Il ne s’agit pas de choisir un langage de programmation, un type de base de données, ni un outil SaaS réputé.
L’enjeu est de définir ce qui colle à son métier et qui fera la différence.
Aujourd’hui, j’observe beaucoup d’entrepreneurs qui ont l’ambition de ré-inventer des activités traditionnelles en perfusant la tech au coeur du métier, et non pas autour.
Des entrepreneurs qui ont compris que le pur métier d’informaticien n’existe pas vraiment. Mais qu’il y a des banquiers qui codent. Des commerçants qui codent. Des fabricants de voitures qui codent.
Bonne semaine !
— Hervé
Si vous aimez cette newsletter et que quelqu’un dans votre entourage pourrait lui aussi l’apprécier, vous pouvez lui partager 👇
Si vous êtes tombés par hasard sur cette newsletter et que le contenu vous intéresse, abonnez-vous aux prochains envois 👇