


Des tuyaux pour de meilleures décisions
Il vous manque peut-être une patte de lapin, ou alors un data engineer

Je rencontre souvent des entrepreneur-e-s qui prennent leurs décisions au flair, à l'instinct. Bref, au feeling.
Des fois ça marche.
Mais ceux qui pilotent un business pérenne et profitable ont plutôt opté pour une autre méthode : prendre des décisions en s'appuyant sur des données.
Le problème est qu'il est souvent compliqué de procéder ainsi, parce que les données sont :
Eparpillées dans plusieurs applications ou fichiers,
Ephémères : les anciennes données sont détruites, remplacées par de nouvelles données
Désynchronisées : elles sont à jour dans un système, mais sont consolidées en fin de mois dans un autre.
Hétérogènes : elles sont organisées différemment dans les fichiers ou bases de données (par numéro article ici, par fournisseur là).
Et lorsqu'on parvient enfin à regrouper toutes ces données, on a seulement parcouru la moitié du chemin.
Pour faire l'autre moitié, il faut encore les présenter à ceux qui en ont besoin, sous une forme compréhensible (indicateurs, graphiques, listes filtrables), et sans douter de leur fiabilité.
Le mois dernier, j'ai consacré pas mal de temps à aider mes clients à fiabiliser leurs données. Et j'ai remarqué un point commun qui pourrait expliquer leurs difficultés : aucune d'entre eux n'a explicitement désigné quelqu'un en charge de cette question.
Personne ne s'occupe des tuyaux.
Oui, tout le monde veut analyser des données fiables, fraîches et en grande quantité. Mais personne ne s'occupe des tuyaux.
Ces tuyaux, les "data pipelines" servent à faire circuler les données entre les endroits ou elles sont produites (fichiers, bases de données, applications externes) et ceux ou on en a besoin.
Et selon la diversité des sources de données, la plomberie peut vite devenir compliquée.

Pour pimenter le tout, ça coule en continu dans les tuyaux : à chaque minute, de nouvelles données sont produites. On est en permanence exposé à un tuyau qui se bouche, ou pire : à une fuite (il manque des données).
Le data-engineering, c'est la plomberie des données. Ca consiste à construire un réseau de pipelines qui distribuent les données vers des consommateurs : les analystes.
Ces analystes peuvent avoir plusieurs profils :
ceux qui veulent comprendre ce qu'il s'est passé. Ex : "quels sont les trajets de covoiturage les plus réguliers à destination de Rennes les matins des jours travaillés ?". C'est le domaine de la BI (Business Intelligence). Il sert à orienter les décisions stratégiques, de long terme.
ceux qui veulent comprendre ce qu'il se passe en ce moment. Ex : "quels sont les chantiers les plus en retard ?". Ils s'intéressent à des données fraîches, pour prendre des décisions opérationnelles, de court terme.
ceux qui veulent prédire ce qu'il va se passer. Ex : "A quelle fréquentation doit-on s'attendre dans notre show-room de Paris le mois prochain ?". C'est le domaine de l'IA, qui va utiliser les données détaillées pour entraîner des modèles de deep-learning.
Depuis quelques années, l'appétit de ces consommateurs devient pantagruélique.
On veut savoir. On veut comprendre. On veut convaincre. On veut anticiper.
ON VEUT DES DONNEES !
OK.
Et qui s'occupe des tuyaux ? Personne.
Ou plutôt si : j'observe que ce sont souvent les analystes qui se chargent d'aller chercher eux-mêmes les données dont ils ont besoin. Parfois avec une canne à pêche, faute de tuyaux.
Pourquoi est-ce plus compliqué qu'un copier/coller ?
Sans pipeline déjà disponible, certains passent beaucoup (trop) de temps à faire cette collecte.
Pourquoi est-ce chronophage ?
Parce qu'on ne peut pas exploiter directement des données brutes.
Les doublons doivent être supprimés. Il faut exclure les cas particuliers, les anomalies ou les valeurs aberrantes. On doit parfois combler des données manquantes, ou encore homogénéiser les formats (ah le cauchemar des dates qui ne sont jamais dans le même format : heure locale ? heure UTC ? Format US ? Format Excel ? ).
Les données évoluent au rythme des changements dans l'entreprise : des entités changent de nom, de nouvelles colonnes apparaissent dans les fichiers Excel.
Le temps consacré par chacun pour se constituer son pipeline personnel de données vient grignoter le temps consacré à analyser les données. Mais ce n'est pas le seul problème.
Vue l'énergie qu'on y a consacré, on n’a surtout pas envie que ça change. Et on finit par lever une armée de réfractaires aux changements, bien conscients du boulot fastidieux qui les attend.
Tout ce temps perdu gagnerait souvent à être investi sur une compétence dédiée.
Le/la data-engineer : son truc c'est les tuyaux.
L'ingénieur.e data (en VF) est celle/celui qui sait construire des pipelines de données. C'est un métier assez récent, et qui nécessite 3 types de compétences :
une compétence métier, pour comprendre la nature des données de l'entreprise,
une compétence d'architecte logiciel, pour établir le plan global des flux et des bases de données,
une compétence technique, pour coder les pipelines et les bases de données qui vont les rendre accessibles aux utilisateurs.
En ce qui concerne les technologies, on trouve dans la caisse à outil du data engineer :
Le SQL, encore indétrônable dans le domaine de la data. Quand on songe que ce langage a été créé en 1974 (et normalisé en 1986) !
Tout ce qui permet de coder des fonctions pour transformer les données : Python et Scala bien sûr, mais aussi des bibliothèques dédiées à la manipulations des données comme Panda ou Apache Spark.
Les bases de données relationnelles (comme Postgresql) ou non (ElasticSearch). On va s'en servir pour rendre les données accessibles aux analystes, aux travers d'outils de visualisation telles que Kibana ou PowerBI.
Les outils d'ETL (Extract, Transform, Load) qui aident à construire les pipelines. On a vu émerger des services en ligne (SaaS) très bien conçus, comme DBT ou Stitch. Mais mon préféré reste Logstash, pour sa concision et son architecture modulaire. Je ne résiste pas à vous en coller un petit extrait :
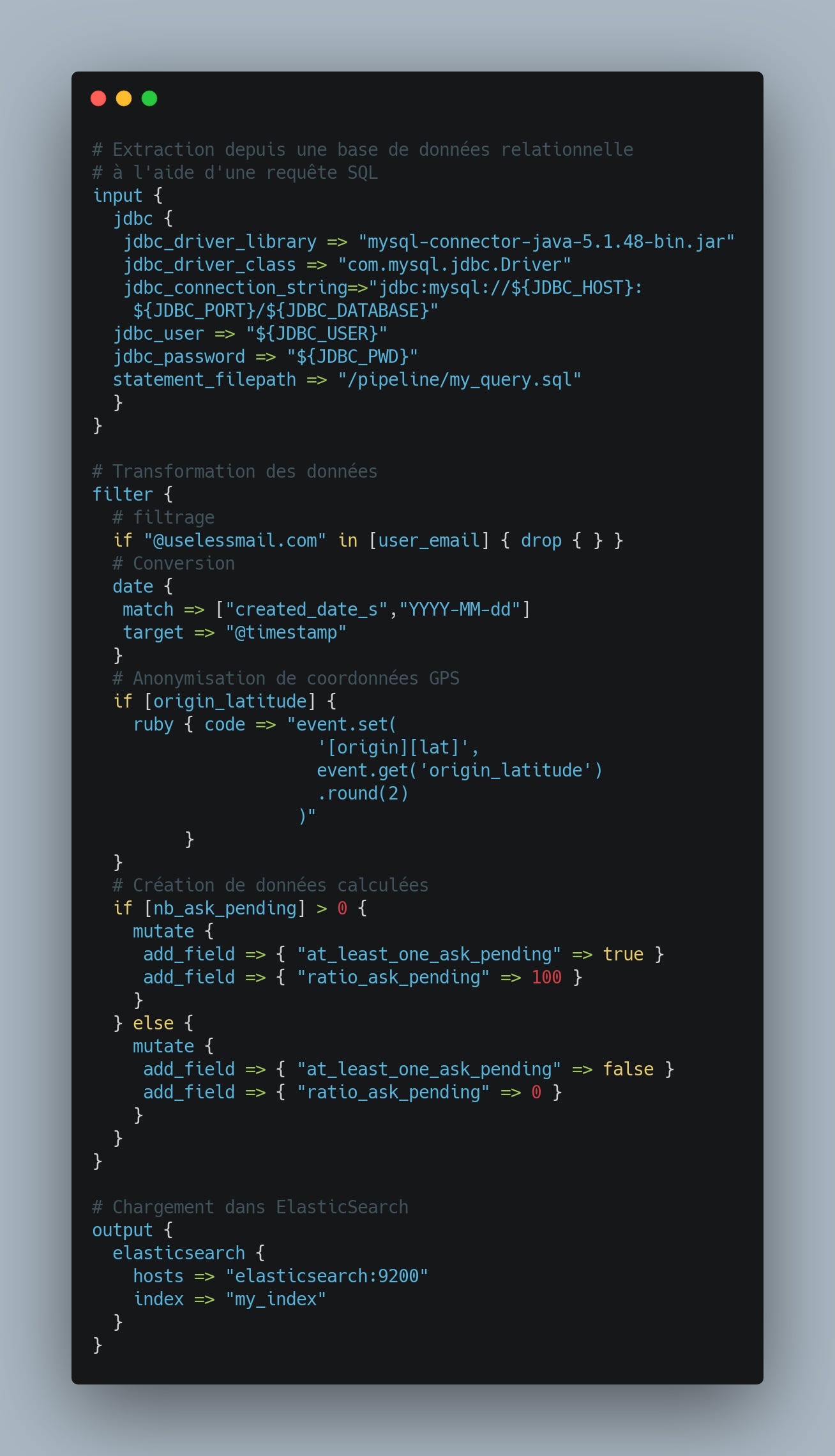
Ce ne sont pas les technos qui manquent !
Mais il y a aussi un volet organisationnel pour maintenir la cohérence d'ensemble lorsque le volume des données s'accroît. Il faut avoir réfléchi à la façon dont on nomme les choses, en particulier :
aux identifiants des données,
aux règles à respecter pour ajouter ou modifier une donnée dans le SI.
Ca se traduit par un coté opérationnel dans le métier du data engineer ("DataOps") pour surveiller que les volumes des données à l'entrées des pipelines restent cohérents avec ceux que l'on trouve à la sortie. Car rien n'est pire que de décider sur la base de données erronées ou manquantes.
Il y a encore peu d'outils qui sont dédiés à ce contrôle qualité. Je ne serais pas surpris d'en voir émerger bientôt.
Bonne semaine, et très bonne année 2021 !
— Hervé